Blog

Visualizing Common Product Metrics Using AI
Chris Stanley

AI Flight Patterns
Brett Sheppard

AI-generated data visualization examples with Patterns + Vega-Lite
Chris Stanley

AI Agents for Decision Support and Decision Augmentation
Chris Stanley

Introducing Patterns
Chris Stanley

Nash's Operational Intelligence Bot, Satoshi II
Chris Stanley

Replacing a SQL analyst with 26 recursive GPT prompts
Ken Van Haren
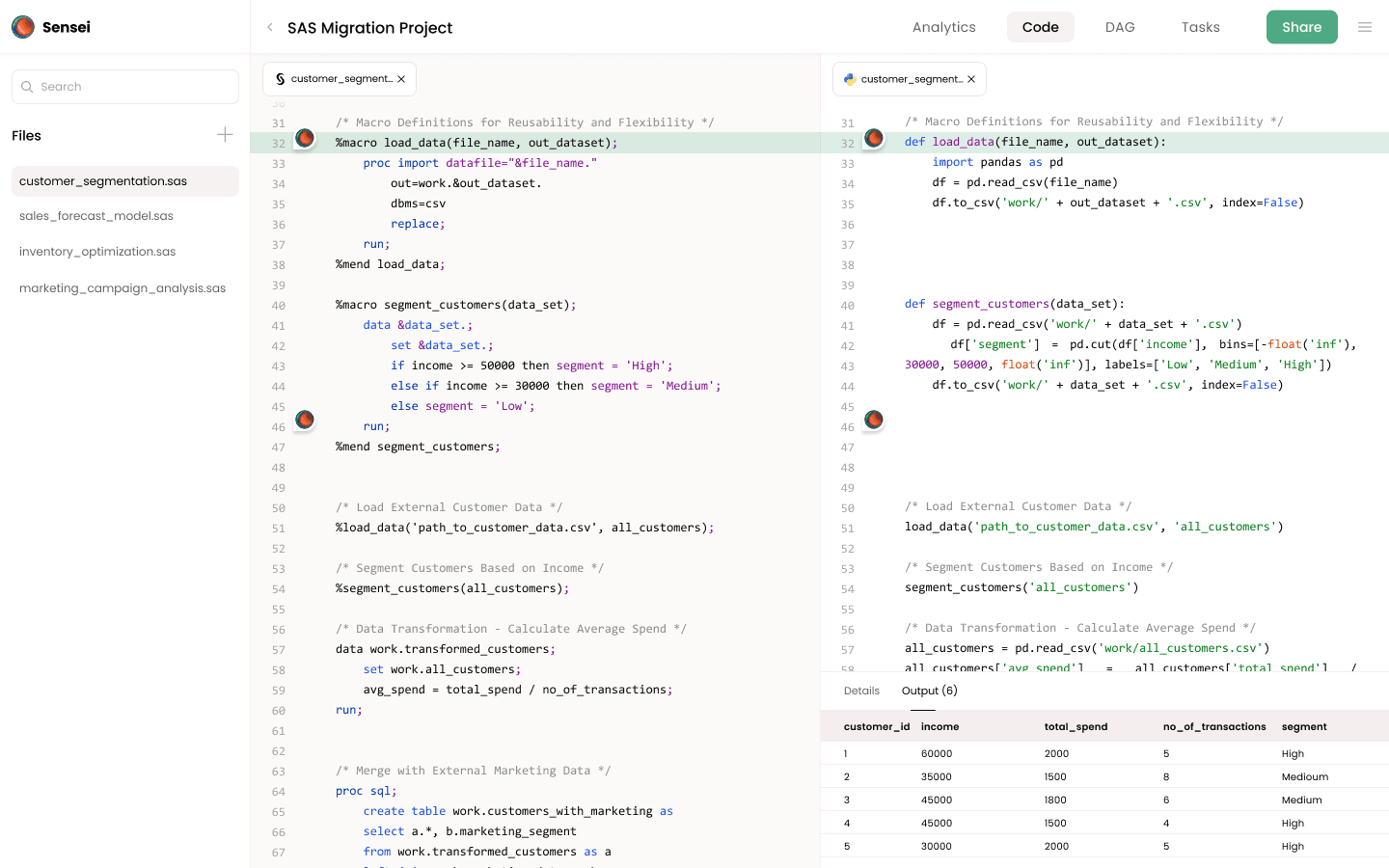
SAS Non-Linear Mixed Effects Model in Python: A Guide
Chris Stanley
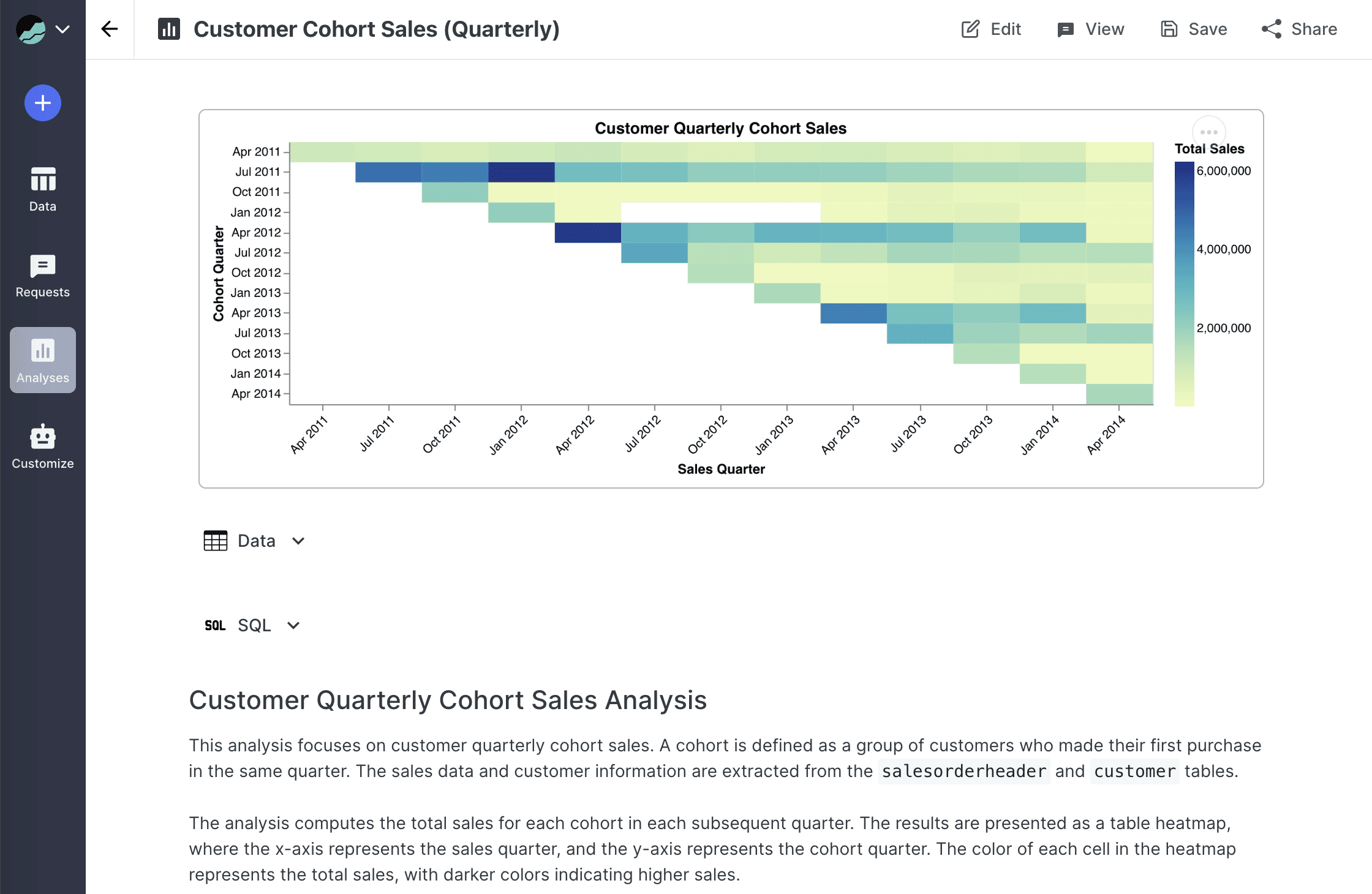
Generate an investor-grade data room in 90 minutes with GPT4
Chris Stanley